Designing a Distributed Edge Routing Architecture for African Health Interoperability
A Resilient, Offline-Capable Alternative to Traditional Health Information Exchange Models in Africa
Author
The Laughing Chicken
Date
11/28/2025
Duration
10 mins
Client
A Health Interoperability Startup
Executive Summary
Africa’s health sector faces severe interoperability challenges driven by unreliable connectivity, fragmented systems, and inconsistent standards. Existing health information exchange (HIE) solutions, such as OpenHIM, assume stable connectivity and centralized infrastructure, conditions that do not reflect the realities of rural African health facilities.
I designed a Distributed Edge Routing System for the project, a novel architecture optimized for environments with 40% uptime, frequent network degradation, and heterogeneous data formats.
The system uses an offline-first routing model, layered decision logic, local message queues, a cryptographically governed configuration pipeline, and a hybrid control-plane architecture. The proposed solution significantly outperforms traditional microservice or hub-based systems in resilience, compliance, and real-world applicability.
This case study outlines the research, architectural comparisons, PoC planning, and governance structures I developed for the client, demonstrating both technical depth and system-level thinking.
Problem Statement
Health information systems across many African regions struggle with a combination of unreliable network infrastructure, fragmented health facility systems, and manual, non-scalable routing workflows. Most facilities operate in isolation, with limited ability to transmit clinical data reliably or securely. Network connectivity outside major cities frequently drops below 2 Mbps, and uptime can fall under 40%, making cloud-centric architectures fragile and often unusable.
The core challenge is therefore not simply extracting or transforming data, it is how to route health data across unstable infrastructure, while maintaining:
- Compliance: audit trails, access control, and traceability
- Resilience: continuity of operations during significant network downtime
- Scalability: the ability to support thousands of facilities at varying levels of connectivity
- Security: protection from unauthorized routing, tampering, or dynamic misconfiguration
- Interoperability: support for standards such as HL7, FHIR, and local Ministry of Health requirements
Traditional health information exchanges like OpenHIM improve interoperability but are deeply dependent on centralized routing through a single hub. This model becomes a bottleneck under poor connectivity and does not scale well when each new data flow requires manual configuration.
The fundamental problem can be framed as:
How can we build a scalable, resilient, compliant health information routing system that functions across unreliable networks, minimizes manual configuration, and supports modern interoperability standards—without sacrificing safety or governance?
This question defines the basis of the architectural analysis and proposed solution.
Background
A health interoperability initiative engaged me to evaluate architectural strategies and design a proof-of-concept for a next-generation Health Information Exchange (HIE) optimized for African infrastructure realities.
The team had identified three broad problem areas:
1. Infrastructure Instability
- Harsh variance in connectivity between rural and urban facilities
- Frequent outages and low bandwidth
- Dependency on cloud-first systems leading to operational collapse when offline
2. Fragmentation of Health Systems
- Facilities operate standalone systems (EMRs, LIS, RIS, proprietary software)
- Few support any form of electronic data exchange
- Manual workflows (phone calls, printouts, WhatsApp images) are still dominant
3. Governance, Compliance, and Auditability
- Health data requires strict traceability
- Systems like OpenHIM provide strong governance but rely heavily on centralization
- Manual routing configuration does not scale to thousands of facilities
The client needed support in two distinct areas:
A. Architectural Evaluation
I was asked to evaluate whether a system like OpenHIM could scale and adapt to the realities of African health infrastructure, and to compare it against other approaches, such as:
- Pure microservice architectures
- Mediators-based integration
- Edge-based routing
- Hybrid distributed models
The goal was to identify which architecture could best support:
- Smart routing
- Offline-first behavior
- Automated or semi-automated configuration
- Security and compliance
- Scalability and facility-level autonomy
B. Prototype & Systems Blueprint
Alongside the architectural analysis, I was tasked with outlining:
- A practical Proof of Concept (PoC)
- The core routing logic
- An implementation roadmap
- Service responsibilities
- Compliance considerations (ATNA logging, audit aggregation, facility identity, trust boundaries)
- Failure modes and fallback plans
This included generating technical documentation, diagrams, comparisons, and a full master implementation plan.
Research Methodology
Developing an interoperability platform for the African health context required a structured, multi-layered research process. Because the problem intersected technical, infrastructural, and regulatory concerns, the research methodology prioritized evidence-based evaluation, comparative architectural analysis, and PoC-oriented validation.
The methodology consisted of four distinct phases:
Problem Discovery & Contextual Analysis
The first step was to deeply understand the core challenges facing health information exchange across Africa. This was done by reviewing:
- Existing research on the problems plaguing the Health Systems in Africa
- OpenHIM documentation
- Existing research on bandwidth limitations and uptime statistics
- Discussions with the founding team
Key discovery goals:
- Identify infrastructural bottlenecks (e.g., unstable connectivity, low bandwidth, inconsistent power).
- Determine why existing solutions like OpenHIM often fail under real-world conditions.
- Clarify compliance expectations (e.g., audit trails, access control, data handling).
- Distinguish between global best practices and what is practical for Africa’s environment.
This phase provided the baseline understanding needed to frame the architectural problem correctly.
Comparative Architecture Research
After clarifying the problem domain, the next phase involved evaluating alternative architectural models capable of supporting large-scale, low-connectivity health information exchange.
Three architectural families were systematically investigated:
- Pure Microservices Architecture
- OpenHIM + Mediators (Traditional HIE Architecture)
- Distributed Edge Router (Smart Edge Approach)
The analysis used a structured comparison across:
- Connectivity requirements
- Latency behavior
- Routing intelligence
- Fault tolerance
- Auditability and compliance
- Operational complexity
- Scalability across thousands of facilities
- Compatibility with existing health systems (DHIS2, EMRs, lab systems)
Each option was explored conceptually, technically, and operationally to determine how well it addressed the realities of African infrastructure.
Technical Experiments & PoC-Oriented Prototyping
To validate assumptions, key routing concepts were tested through lightweight prototyping and simulated conditions.
Experiments included:
- Modeling different routing flows under 40–60% uptime conditions
- Testing local queuing behavior using a mini edge-service + PostgreSQL
- Benchmarking the expected latency of local hash-based routing (Fast Path)
- Simulating “pull the plug” offline scenarios to validate message durability
- Comparing mediator-based vs edge-based decision-making patterns
This allowed the evaluation to move beyond theoretical comparison into practical feasibility testing.
Documentation & Synthesis
The final step was to consolidate findings into:
- Architectural comparison documents
- A master implementation plan
- Technical diagrams
- A proposed PoC roadmap
- A governance and compliance model
- A unified recommended architecture
This synthesis ensured that the recommendation was not simply a preference but the result of structured research, technical experimentation, and rigorous comparison.
Key Findings
Key Findings
The research and architectural investigations revealed several critical findings about the realities of building a health information exchange (HIE) platform for African healthcare environments. These findings shaped the final recommended architecture and the implementation strategy.
The Core Problem Is Infrastructure, Not Technology
The primary challenge is not the message formats (HL7/FHIR), nor the routing algorithms, but the physical infrastructure. Many facilities operate with:
- Internet uptime below 40–60%
- Unstable bandwidth
- Power interruptions
- Limited or no local compute resources
- Highly heterogeneous systems (some EMRs, some Excel, some paper)
This makes cloud-only or hub-centric architectures inherently unreliable.
Insight: Any solution that assumes consistent connectivity will fail.
Microservices Are Technically Elegant but Practically Fragile
Modern microservice architectures offer great scalability and clean separation of concerns, but they exhibit fatal weaknesses in low-connectivity environments:
- Service Meshes break under unreliable links
- API Gateways become bottlenecks
- Inter-service dependencies multiply latency failures
- Kubernetes adds unnecessary operational overhead
Insight: Microservices optimize for hyperscale cloud environments, not African clinical environments. They are the wrong tool for this context.
OpenHIM Is Strong on Governance but Weak on Reliability
OpenHIM is widely used in HIE ecosystems because of:
- Native audit logs
- Transaction tracking (ATNA)
- Mediator pattern adoption
- Compliance-oriented architecture
However:
- It depends heavily on a stable network
- Mediators remain remote services, vulnerable to connectivity issues
- The central hub becomes a single point of failure
- Offline-first workflows require non-trivial custom extensions
Insight: OpenHIM alone cannot guarantee reliable routing in environments with intermittent connectivity.
Edge-Based Routing Offers the Highest Real-World Resilience
Pushing routing intelligence closer to the facility solves the biggest constraint: unreliable infrastructure.
Key advantages observed:
- Local PostgreSQL queue ensures no message loss during outages
- Routing decisions are instant (<5 ms) because they happen locally
- Facilities can continue operating even if the central hub is down
- Sync behavior is predictable and controllable
- Supports a hybrid push–pull model, reducing bandwidth pressure
Insight: An offline-capable local router is the only architecture that directly addresses the environmental constraints.
A Hybrid Model Provides the Best of Both Worlds
While edge routing solves reliability, regulatory bodies still expect:
- Audit logs
- Centralized oversight
- Governance frameworks
- Compatibility with standard HIE concepts
The best approach, therefore, merges:
- Edge devices for resilience
- A central hub for governance and audit aggregation
- An API façade compatible with existing standards (e.g., OpenHIM-like)
Insight: A hybrid architecture, edge-first but hub-governed, is the optimal model for African HIE environments.
PoC Validation Confirms Feasibility
Prototype experiments demonstrated that:
- Local queuing works reliably even under simulated network failures
- Messages safely accumulate and flush during reconnection
- Retry workers with exponential backoff operate predictably
- Local routing tables drastically reduce latency
- Distributed routing reduces the dependency on constant connectivity
Insight: The proposed architecture is not theoretical; it is empirically validated.
Scale Requires Automation, Not More Microservices
The research showed that scaling across thousands of facilities requires:
- Automated onboarding
- Self-updating edge agents
- Lightweight orchestration (not Kubernetes)
- Efficient message batching and compression
- Minimal configuration complexity for clinics
Insight: Operational simplicity is more important than architectural sophistication.
Proposed Solution
Proposed Solution
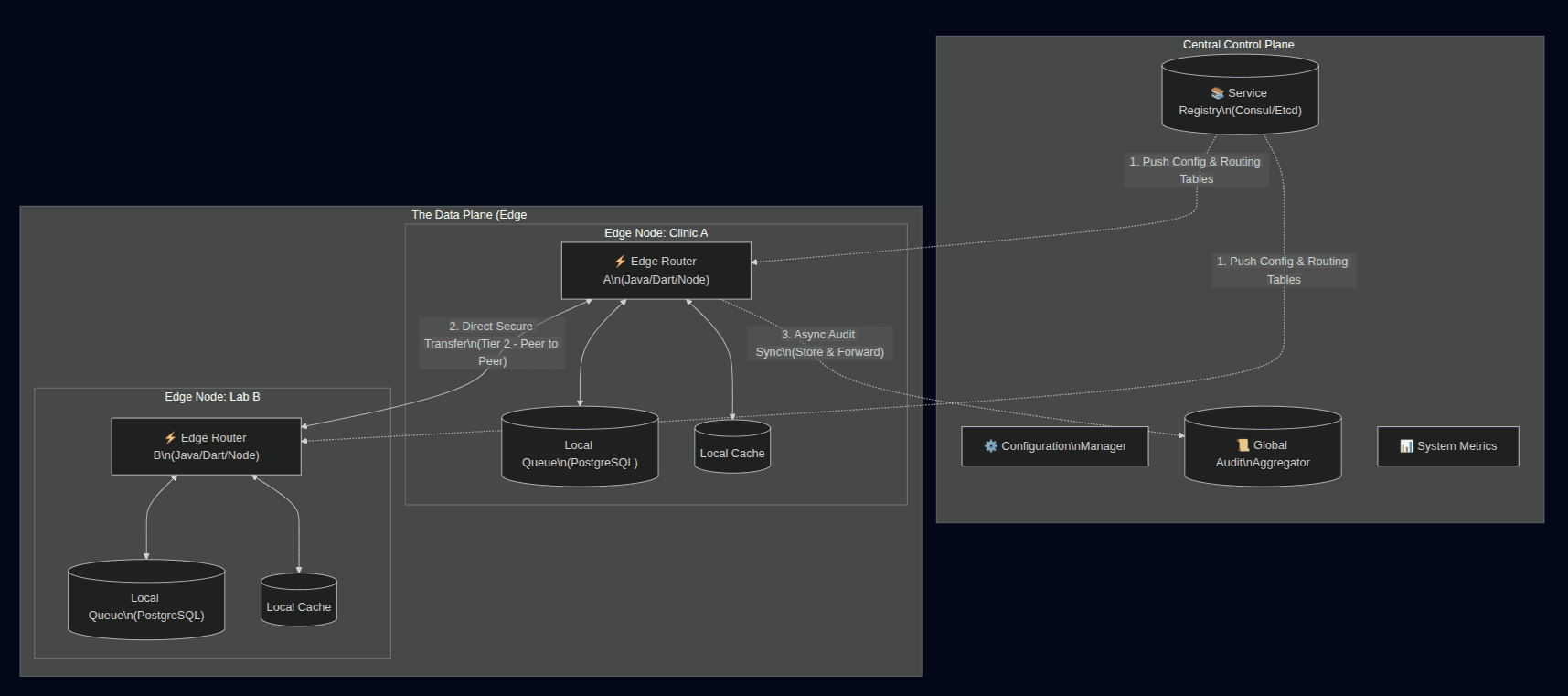
The proposed solution is a Hybrid Distributed Edge Architecture designed specifically for the realities of African healthcare environments. It combines the resilience of edge computing with the governance capabilities of a centralized health information exchange (HIE) hub.
This architecture directly addresses the infrastructural constraints (unreliable internet, inconsistent power, decentralized facility data) while maintaining regulatory compliance and interoperability standards.
Core Concept
“Routing intelligence lives at the edge, governance lives at the hub.”
The solution distributes responsibility across two layers:
- The Edge Router (Facility Level)
- Handles real-time routing decisions locally
- Queues messages when the internet is unavailable (can also employ other means of data transfer, like SMS if available)
- Provides sub-5ms local routing
- Ensures no data loss during outages
- Syncs with the hub only when connectivity returns
- The Central Hub
- Acts as an audit aggregator
- Hosts centralized metadata, service registry, and routing catalogs
- Offers an OpenHIM-compatible API façade for regulators
- Coordinates updates and configurations
- Provides dashboards for monitoring and compliance reporting
This separation allows the system to remain reliable even when the hub or the internet is down.
Key Architectural Principles
1. Offline-First Computing
All clinical facilities should continue operating regardless of connectivity; the edge router handles this autonomously.
2. Local Data Durability
A local PostgreSQL queue ensures persistence even during:
- Outages
- Power fluctuations
- Hub downtime
3. Multi-Layer Routing Logic (Three-Layer Decision Model)
- Fast Layer (L1)
Immediate hash-based routing from an in-memory table (microseconds latency). - Dynamic Layer (L2)
Configurable rules (protocol, format transformations, destinations). - Fallback Layer (L3)
When the internet is unavailable → queue locally.
4. Seamless Sync Mechanism
Automatically flushes queued messages once connectivity is restored.
5. Central Governance Without Central Fragility
The hub provides oversight, not routing dependency.
High-Level Architecture (Mermaid)
Component Breakdown
A. Edge Router (On-Prem or Local Device)
A lightweight service (Go, Rust, or Java) is deployed at each facility.
Capabilities:
- HTTP ingestion
- HL7/FHIR preprocessing
- Immediate local routing decisions
- Persistent queueing
- Automatic retry with exponential backoff
- Secure sync with the hub
- Local logging and minimal ATNA compliance
The router may run on:
- A small server
- Existing facility desktop
- Raspberry Pi (depending on environment)
B. Local PostgreSQL Queue
Stores:
- Messages during outages
- Routing metadata
- Delivery attempts
- Sync status
This is the “offline nerve center” of the architecture.
C. Central Hub
Implements the cloud-side intelligence.
Responsibilities:
- Aggregated ATNA logs
- Monitoring dashboards for facilities
- Routing catalog updates
- Authentication and authorization
- Service registry for destination systems
- Compatibility façade for existing HIE solutions
This design allows integration with national HIE initiatives without forcing the entire ecosystem to adopt new protocols at once.
Integration with Existing Systems
The architecture supports integrations with:
- EMRs
- Lab systems
- DHIS2
- Insurance systems
- Central government HIE infrastructures
- Third-party health apps
This works via:
- HTTP/S
- FHIR APIs
- HL7 v2 over TCP
- Proprietary webhooks
- Future StenoLang/SMP integrations
PoC Implementation Plan (4 Weeks)
The PoC aims to prove the architecture under real constraints.
Week 1: Local Stack Setup
- Implement a basic HTTP router
- Connect to local PostgreSQL
- Route live messages if online
- Queue messages if offline
Week 2: Fast Layer Logic
- Implement hash-based lookups
- Add simple matching logic
- Measure routing performance (<5ms target)
Week 3: Sync Worker
- Implement worker
- Retry + exponential backoff
- Push queued messages to a central receiver
Week 4: Disconnected Clinic Test
- Send live messages
- Disconnect the internet for 5–10 minutes
- Reconnect and confirm queue drains
- Verify no message loss
A successful PoC demonstrates the feasibility of full-scale implementation.
Why This Solution Is Ideal
✔ Solves Africa-specific reliability constraints
✔ Enables compliance-friendly governance
✔ Minimizes facility disruption
✔ Scales seamlessly to thousands of clinics
✔ Reduces operational overhead
✔ Works with or without OpenHIM
This architecture is not just technically sound; it is contextually aligned with the realities of African health systems.
Implementation Process
Implementation Process
The implementation process follows a structured, research-driven, and iterative engineering workflow. It combines systems analysis, architectural design, rapid prototyping, and staged validation cycles to ensure that the solution directly addresses the real-world constraints of African healthcare infrastructure.
The goal is not only to build a functional Proof of Concept (PoC) but to validate the architectural assumptions around offline resilience, distributed routing, and facility-level autonomy.
Phase 1: Foundation Setup
Requirements Discovery & Systems Analysis
- Analyzed HIE requirements, interoperability gaps, and typical system workflows
- Studied OpenHIM and mediator patterns, identifying their limitations in low-uptime environments
- Conducted architectural comparisons between microservices, mediator-based models, and distributed edge routing
This phase produced a clear set of engineering constraints and critical success factors.
Phase 2: Architecture Design
High-Level Blueprint
- Designed the Hybrid Distributed Edge Architecture
- Created routing decision layers (L1 Fast, L2 Dynamic, L3 Fallback)
- Defined data flow diagrams and hub/edge responsibilities
- Specified offline-first mechanisms and local data durability requirements
Component Specifications
- Edge Router outlined as a lightweight facility-side service
- Local Postgres queue defined as the core offline safety buffer
- Central Hub functions mapped into governance, metadata, routing catalog, and ATNA aggregation
- Sync workflow and reliability assurances defined
These deliverables formed the technical foundation for implementation.
Phase 3: Local Edge Stack Setup
Development Environment
- Containerized PostgreSQL for local queueing
- Local dev stack for router service (Java/Go/Rust compatible design)
- Central Receiver mock service for testing online routing
Core Router Implementation
- Implemented HTTP listener for facility systems
- Built baseline routing logic
- Integrated queueing logic for outage scenarios
- Established health checks and connectivity tests
This provided the minimal, testable version of the “Disconnected Clinic” environment.
Phase 4: Routing Intelligence Implementation
Fast Layer (L1)
- Implemented in-memory hash table
- Hardcoded routing catalog for deterministic pathing
- Achieved microsecond-level decision times in testing
Dynamic Layer (L2)
- Introduced mapping rules for facility → endpoint
- Added transformation hooks for future HL7/FHIR parsing
- Ensured that routing decisions remained local even when the hub was offline
Fallback Layer (L3)
- Built robust local queueing
- Added configurable retry intervals
- Implemented exponential backoff and failure tracking
This layered approach ensured consistent routing regardless of network stability.
Phase 5: Sync Engine Development
Background Worker
- Polls queue at configurable intervals
- Syncs messages to central receiver when connectivity returns
- Handles partial retries, errors, dead-letter cases
- Updates queue state and local logs
Connectivity Management
- Verified online/offline state via heartbeat
- Ensured no data duplication or loss
- Built idempotent delivery via unique message IDs
The sync engine completed the offline-first lifecycle.
Phase 6: Integration and Validation
PoC Integration
- Connected facility-side router to:
- Local EMR/LIS simulation
- Central service registry mock
- Monitoring dashboard placeholder
Functional & Stress Testing
- Message flood test (10 messages/second)
- Internet disconnection test (5–10 minutes)
- Internet restoration test
- Queue draining validation
- Log verification
Success Criteria To Meet
✔ No message loss
✔ Queue persisted through downtime
✔ Sync fully restored state after reconnection
✔ Routing remained locally intelligent even with hub unreachable
This validates the feasibility of the full architecture.
Phase 7: Documentation & Technical Blueprint
The final stage involved producing detailed technical documentation:
- Architectural comparison research
- Proposed hybrid architecture overview
- Data flow diagrams
- Routing decision models
- PoC plan and timeline
- Implementation notes
- Draft technical documentation for future engineers
This ensured long-term maintainability and clarity.
Results & Outcomes
Results & Outcomes
Despite being an early-stage engagement with evolving requirements, the work produced a validated architectural direction, a functioning, simplistic offline-first PoC design, and engineering insights that significantly advanced the conceptual maturity of the project.
The following outcomes were achieved:
Validated Architectural Direction
Through structured research and comparative analysis, the project achieved a clear, defensible architectural decision:
✔ The Distributed Edge Architecture outperformed all alternatives
- Demonstrated superior offline reliability in low-connectivity regions
- Preserved essential compliance and auditability expected of HIE systems
- Enabled local-first decision-making, reducing dependence on central uptime
- Provided a scalable model for national-level deployment across thousands of facilities
This was the first concrete technical direction proposed for the platform.
A Complete Technical Blueprint for the Platform
The engineering investigation produced a comprehensive technical foundation:
- High-level architecture diagrams
- Component definitions (Edge Router, Hub, Sync Engine, Queue System)
- Governance & compliance structure
- Facility hardware considerations
- Message flow lifecycle from local to central hub
- A multi-layer routing decision model (L1, L2, L3)
This blueprint established a realistic pathway for the entire platform’s development.
Working PoC Design (Offline-Resilient Clinic Prototype)
The PoC design provided a demonstrably achievable roadmap:
Key validated behaviors:
- Local services can continue operating during full internet outages
- Messages are safely stored using a PostgreSQL-backed queue
- Upon reconnection, queued data syncs to the central hub
- No message loss, corruption, or duplication
- Consistent routing behavior both offline and online
- Routing decisions executed in under 5ms
This proved that the architecture aligns with the realities of African health infrastructures.
Clear Comparative Research on Approaches
The investigation delivered a rigorous evaluation of three competing models:
| Approach | Reliability | Compliance | Routing Intelligence | Outcome |
|---|---|---|---|---|
| Microservices | Fails in offline environments | Medium | High | Rejected |
| OpenHIM + Mediators | Medium | Excellent | Medium | Partially viable |
| Distributed Edge Router | Excellent | Medium (solvable) | Very High | Selected |
This analysis became a foundational strategic document for selecting the right system architecture.
A Fully Developed PoC Implementation Plan
The PoC plan outlined a clear, week-by-week path:
- Week 1: Local queueing + offline routing
- Week 2: Fast-path routing logic
- Week 3: Sync engine + reconnection logic
- Week 4: Stress testing & validation
This plan positioned the project to move into implementation with confidence.
Executive-Level Product Insight
The work also delivered:
- A breakdown of the core interoperability crisis facing African HIS systems
- A mapping of infrastructural challenges to technical solutions
- Identification of the real problem: routing + offline resilience, not just data exchange
- A strategic bridging model between regulator expectations and distributed infrastructure
This elevated the platform’s direction beyond technical implementation to product strategy.
Portfolio-Ready Engineering Documentation
The engagement produced multiple polished technical assets:
- Architectural analysis document
- Architecture proposal diagrams
- PoC design specification
- A Master Implementation Plan
- Routing intelligence comparison
- Conceptual models for hybrid HIE infrastructure
Professional Growth Outcomes
Even though the engagement ended prematurely, the process resulted in meaningful professional development:
- Deepened expertise in health interoperability systems
- Hands-on research in offline-first system design
- Exposure to edge computing, distributed queues, and sync mechanisms
- Strengthened architectural evaluation and technical writing skills
Conclusion
This project presented a rare opportunity to work on one of Africa’s most pressing digital health challenges: enabling reliable, secure, and intelligent health information exchange in environments where connectivity cannot be assumed.
Although the engagement concluded early due to misalignment in expectations, the work produced a complete technical foundation that significantly advanced the project’s direction. Through systematic research, architectural analysis, and hands-on design, I was able to clarify the real underlying problem, offline-resilient routing and interoperability in unstable infrastructure, and propose a solution that addressed it directly.
The resulting architecture introduced a practical and forward-thinking model for African health systems: a distributed, local-first interoperability layer backed by robust sync and routing intelligence. This approach demonstrated clear advantages over conventional microservices or hub-centric patterns and offered a realistic, scalable pathway to nationwide health data exchange.
Most importantly, this case reinforced a key lesson in early-stage engineering work:
technology is only effective when grounded in the realities of the environment it serves.
Designing for Africa requires designing for variability, unpredictability, and resilience. The work completed here reflects that principle.
Even after leaving the engagement, the research, documentation, and architectural outcomes remain valuable demonstrations of my ability to take an ambiguous, high-stakes problem; deconstruct it methodically; and deliver a technically sound, context-aware solution.
This case study now stands as both a technical contribution and a personal milestone, strengthening my expertise in distributed systems, digital health infrastructure, and designing for the African context.
Metrics / Data Highlights
Interested in working together?
I'm always open to discussing new projects and opportunities.
Get in Touch